First article of a series on enabling modern ALM practices for an Azure Stream Analytics project.
- Part 1 : 100 - The story of 2 pipelines
- Part 2 : 101 - Local developer experience
- Part 3 : 102 - Provisioning scripts and live job
- Part 4 : 103 - Continuous build
- Part 5 : 104 - Automated deployment
- Part 6 : 105 - Unit testing
- Part 7 : Integration testing - to be written
Context
Data streaming is awesome. Azure is awesome. Let’s build a real time data pipeline using Azure Stream Analytics then! And now with the cloud and DevOps, let’s do things right and “Infrastructure as Code” and “CI/CD” all the things!
Or so I told myself before struggling with implementation details so frustrating, I almost quit data engineering entirely. I reassured myself with the thought that pain is often good evidence that work is being done on something that matters. Right?
To really benefit from what follows, one should have already played a little bit with Azure Stream Analytics (ASA). I expect it to be the case directly in the Azure portal. This article focus on moving out of the portal, and considering the ALM (Application Lifecycle Development) aspects of that transition. There is nothing below about a use case or scenario, the query or the data pipeline itself.
PipelineS
As for everything “DataOps”, we’re going to have to consider two pipelines (at least). On one side, there’s the data pipeline: the real time one that ASA enables. On the other side, there’s the development pipeline: the meta one that takes our code from our IDE through staging and eventually production.
This schema from DataKitchen shows how data is moving left to right, and code is moving bottom to top:
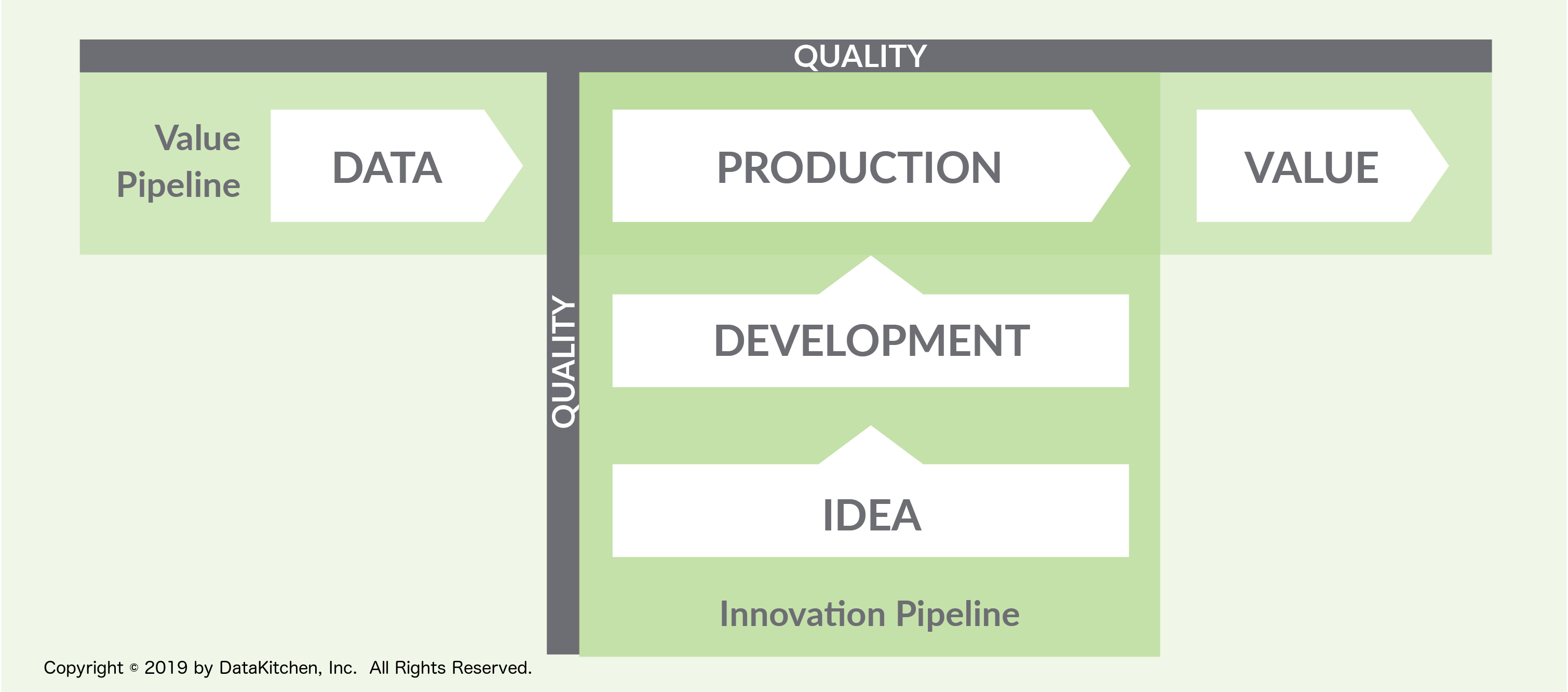
figure 1 - Two pipelines: data and code - Copyright Data Kitchen
Azure Stream Analytics is the main engine of the streaming pipeline.
Azure DevOps is the main engine of the development pipeline, both with Azure Repos and Azure Pipelines.
The plan is to set up a local development environment disconnected from Azure, either using Visual Studio or Visual Studio Code (VSCode). There we’ll create an ASA project and write a simple data pipeline that reads data from a sample input, runs a basic query locally and outputs that to disk. We will check that project in Azure Repos using Git. We should also write some scripts to provision the infrastructure we will later need on Azure when time comes to deploy. From there we’ll setup a build (we’ll see what it means in our context) and a release pipeline to a staging environment.
Components
Taking all that into account, we can start to assemble our puzzle:
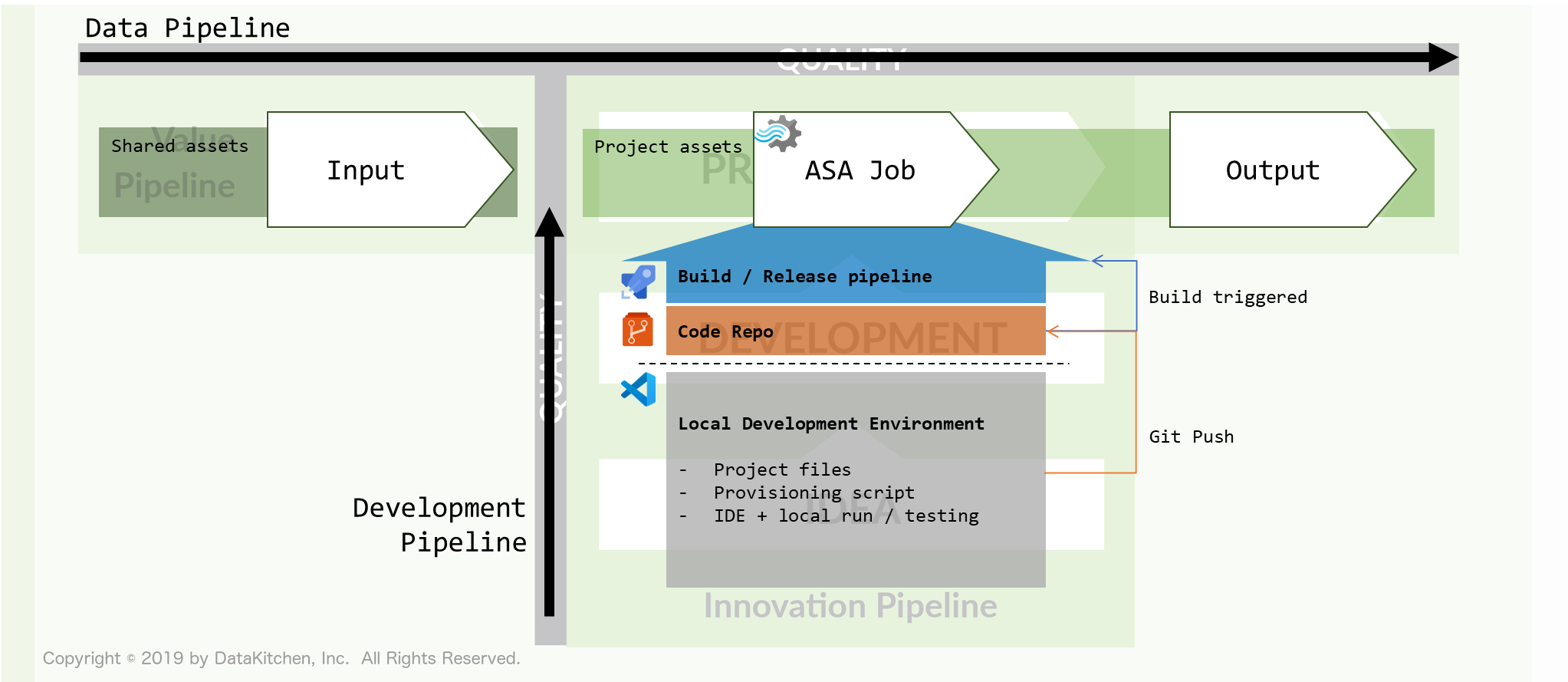
figure 2 - Making that schema ours
Of course an actual release pipeline will be more complex than a simple local development-to-staging flow. But if we get the basic wiring right, we can add as many intermediary steps or targets as necessary (staging, integration, UAT, pre-prod, prod…).
Now if we want to do proper local development, we expect to be able to do local runs on local inputs and outputs. Local runs will be enabled by the ASA extensions available for VSCode and Visual Studio. Using local inputs/outputs, with sample data, is a supported scenario both in VSCode and Visual Studio.
Let’s focus on a single IDE from now on, and pick VSCode. The main reason is that I’ve been enjoying it a lot lately, using it remotely on the WSL. I don’t expect things to be too different using Visual Studio instead (note from future self: you’re wrong, but that’s not important).
The last thing we need to be aware of is that ASA jobs are deployed via ARM templates. ARM Templates are JSON files that describe a specific Azure resource, here an ASA job. ARM templates are usually made of 2 files: one that describes the resource itself, and one that holds parameters (connection string, credentials…). The ASA extension will handle those files for us, “compiling” our ASA assets (query file, input/output files, config files) into ARM template files.
Taking all that into account, at the end of our local setup we should get something like this (yes it’s a bit of a spoiler, and we’ll discuss everything on that picture and leave no stone unturned):
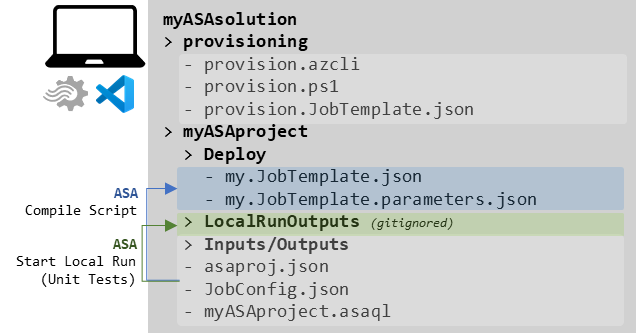
figure 3 - A representation of the assets discussed above
Once this is done, in the rest of the series we’ll discuss the data pipeline running in Azure, and the CI/CD pipeline in Azure DevOps.
Let’s dig in.
Next steps
Part 1: 100 - The story of 2 pipelines- Part 2 : 101 - Local developer experience
- Part 3 : 102 - Provisioning scripts and live job
- Part 4 : 103 - Continuous build
- Part 5 : 104 - Automated deployment
- Part 6 : 105 - Unit testing
- Part 7 : Integration testing - to be written
