Notable implementation details of a hybrid batch data pipeline using ADFv2.
This is article is part of a series:
- Architecture discussion
- ALM and Infrastructure
- Notable implementation details <- you are here
Original publication date : 2018-12
Architecture
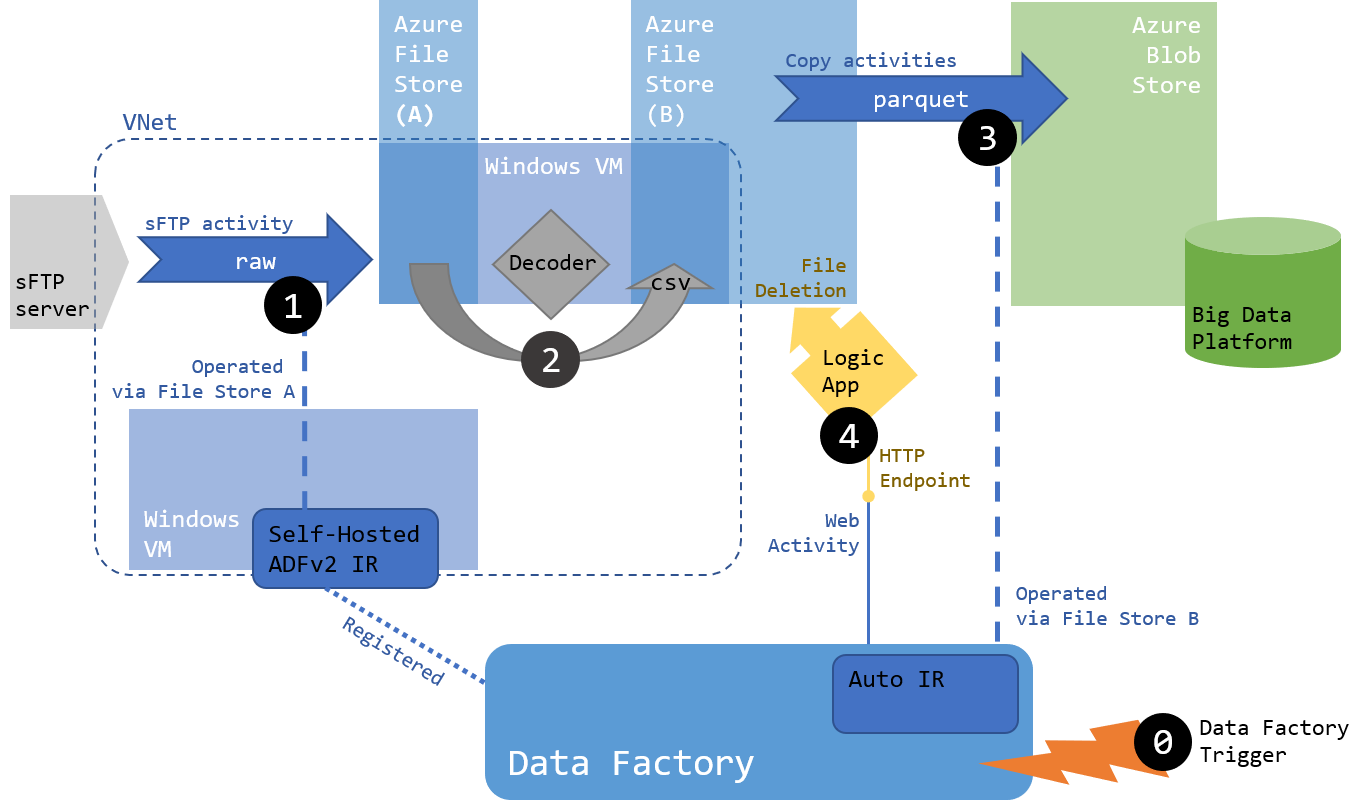
As a reminder, here is the solution architecture we established earlier (see the first article of the series for more details):
Implementation in ADFv2
We will focus on the implementation of Step 3 and 4 in Azure Data Factory v2 as they contain most of the logic in our pipeline:
- Step 3
- Get data from File Store B
- Flatten the hierarchy of folders (see chart below)
- Convert files from CSV to Parquet
- Step 4
- Delete files when processed

Logical flow
If the Copy Activity of ADFv2 allows for a flattening of the file structure when copying files, it auto generates a name for them in the operation. We decided instead to loop over the folder structure ourselves, gathering metadata as we go, to iterate over individual files and process them as required (copy, rename, delete).
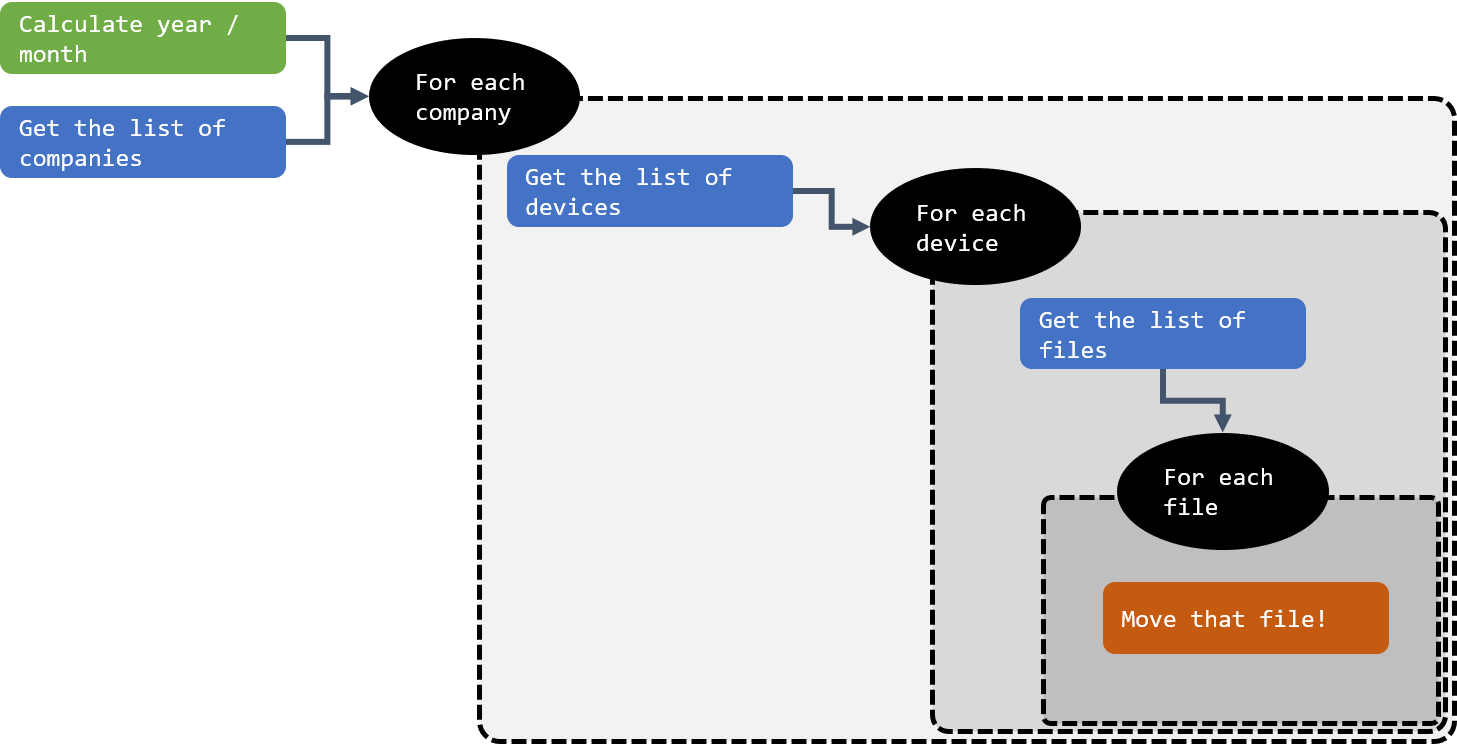
We will use 3 levels of nested loops to achieve that result:
- Iterating over Companies
- Within a company for the current year/month, iterating over Device IDs
- Within a company for the current year/month for a Device ID, iterating over individual files
- Within a company for the current year/month, iterating over Device IDs
We won’t loop over Year/Month as we’re only processing the current day of results, and we can generate these attributes using the current date.
At the time of writing it is not possible to nest a ForEach activity inside another ForEach activity in ADFv2. What should be done instead is to execute a pipeline in a Foreach and implement the next loop in that second pipeline. Parameters are used to transmit the current item value of the loop between nested pipelines. This is detailed below.
Here is an illustration of the expected logical flow:
Data sets
We will use parameters in our data sets following that strategy.
To iterate over the file structure in the File Store B, we will need:
- FS_Companies : point to the root folder containing the list of companies
- Binary Copy (no metadata to be loaded) with a folderPath only (see green tip infobox)
- FS_DeviceIDs : point to a folder of Device Ids
- Parameters : Company, Year, Month
- Binary Copy, folderPath only
- folder path:
@concat(dataset().Company,'/',dataset().Year,'/',dataset().Month)
- folder path:
- FS_Files : point to a folder of files
- Parameters : Company, Year, Month, Device Id
- Binary Copy, folderPath only
- folder path:
@concat(dataset().Company,'/',dataset().Year,'/',dataset().Month,'/',dataset().DeviceID)
- folder path:
- FS_File : point to a specific file to be processed
- Parameters : Company, Year, Month, Device Id, FileName
- CSV format
- folder path:
@concat(dataset().Company,'/',dataset().Year,'/',dataset().Month,'/',dataset().DeviceID) - file path:
@dataset().FileName - Schema : column names loaded from file, data types should be generated manually and entered here (an explicit conversion is mapped from source)
- folder path:
We don’t need data sets to iterate over years and months as we can extract that from the current date. We will expose those as parameters to be able to process the past if need be.
On the output side, we will need a sink data set targeting the blob store:
- BS_OutputFile : point to a specific file to be generated
- Parameters : Company, Year, Month, Device Id, FileName
- Parquet format
- file path:
@concat(dataset().Year,dataset().Month,'_',dataset().Company,'_',dataset().DeviceID,'_',dataset().FileName) - schema : generated manually with cleaned column names (no space/symbol for Parquet) and explicit data types
- file path:
Pipeline design
Here are the pipelines that will be created:
Pipeline “01 - Master”
Parameter:
- LogicApp_FS_Delete: Logic App URL
This is the master pipeline for step 3/4. It will contain the main routine and eventually some additional administrative steps (audit, preparatory and clean-up tasks…).
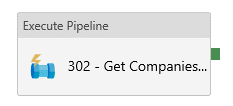
- Execute Pipeline Task : 02 - Get Companies and IDs
- Invoked Pipeline : “02 - Get Companies and IDs”
- Parameters :
@pipeline().parameters.LogicApp_FS_Delete
Pipeline “02 - Get Companies and IDs”
Parameter:
- LogicApp_FS_Delete: Logic App URL, String
Variables:
- PipeMonth : String
- PipeYear : String
This pipeline will get the list of companies from the folder metadata, generate the current Year/Month, and from that get the list of available Device IDs from the subfolder metadata.
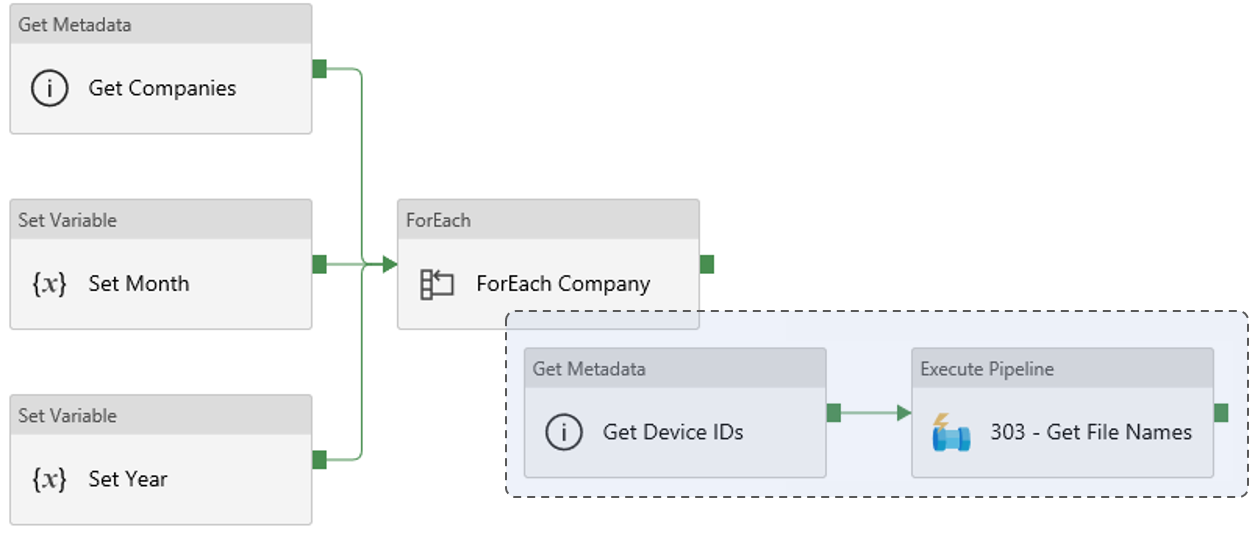
- Get Metadata : Get Companies
- Dataset : FS_Companies
- Field List Argument : Child Items
- Set Variable : Set Month
- Variable :
PipeMonth - Value :
@formatDateTime(adddays(utcnow(),-1),'MM')
- Variable :
- Set Variable : Set Year
- Variable :
PipeYear - Value :
@formatDateTime(utcnow(),'yyyy')
- Variable :
- ForEach : Foreach Company
- Items :
@activity('Get Companies').output.childItems - Activities :
- Get Metadata : *Get Device IDs”
- Dataset : FS_DeviceIDs
- Parameters :
- Company :
@item().name - Year :
@variables(*PipeYear*) - Month :
@variables(*PipeMonth*)
- Company :
- Parameters :
- Field List Argument : Child Items
- Dataset : FS_DeviceIDs
- Execute Pipeline : 03 - Get File Names
- Invoked Pipeline : “03 - Get File Names”
- Parameters :
- LogicApp_FS_Delete :
@pipeline().parameters.LogicApp_FS_Delete - PipeCompany :
@item().name - PipeYear :
@variables(*Var_Year*) - PipeMonth :
@variables(*Var_Month*) - PipeDeviceIDList :
@activity('Get Device IDs').output.childItems
- LogicApp_FS_Delete :
- Get Metadata : *Get Device IDs”
- Items :
Pipeline “03 - Get File Names”
Parameters:
- LogicApp_FS_Delete: Logic App URL, String
- PipeCompany : String
- PipeYear : String
- PipeMonth : String
- PipeDeviceIDList : Array
This pipeline will get the list of file names from the final subfolder metadata.
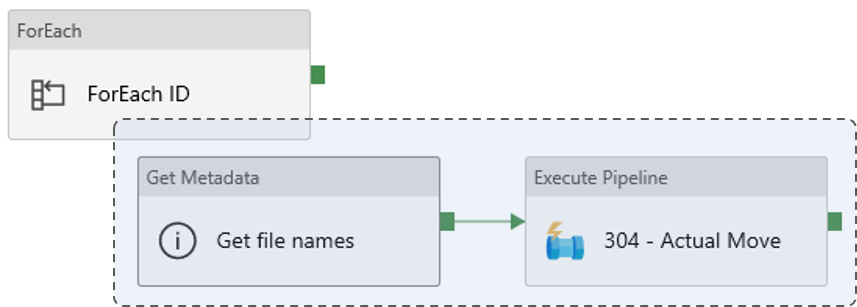
- ForEach : ForEach ID
- Items :
@pipeline().parameters.PipeDeviceIDList - Activities :
- Get Metadata : *Get file names”
- Dataset : FS_Files
- Parameters :
- Company :
@pipeline().parameters.PipeCompany - Year :
@pipeline().parameters.PipeYear - Month :
@pipeline().parameters.PipeMonth - Device ID :
@item().Name
- Company :
- Parameters :
- Field List Argument : Child Items
- Dataset : FS_Files
- Execute Pipeline : 04 - Actual Move
- Invoked Pipeline : “04 - Actual Move”
- Parameters :
- LogicApp_FS_Delete :
@pipeline().parameters.LogicApp_FS_Delete - PipeCompany :
@pipeline().parameters.PipeCompany - PipeYear :
@pipeline().parameters.PipeYear - PipeMonth :
@pipeline().parameters.PipeMonth - PipeDeviceID :
@item().Name - PipeFileNames :
@activity('Get file names').output.childItems
- LogicApp_FS_Delete :
- Get Metadata : *Get file names”
- Items :
Pipeline “04 - Actual Move”
Parameters:
- LogicApp_FS_Delete: Logic App URL, String
- PipeCompany : String
- PipeYear : String
- PipeMonth : String
- PipeDeviceID : String
- PipeFileNames : Array
This pipeline will copy and then delete the files.
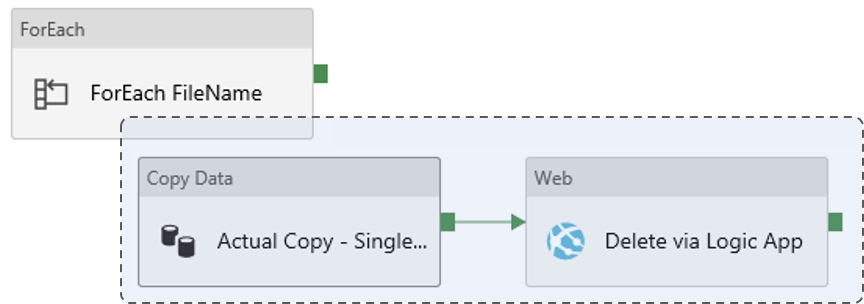
- ForEach : ForEach FileName
- Items :
@pipeline().parameters.PipeFileNames - Activities :
- Copy Data : Actual Copy - Single File
- Source : FS_File
- Parameters :
- Company :
@pipeline().parameters.PipeCompany - Year :
@pipeline().parameters.PipeYear - Month :
@pipeline().parameters.PipeMonth - Device ID :
@pipeline().parameters.PipeDeviceID - FileName :
@item().Name
- Company :
- Parameters :
- Sink : BS_OutputFile
- Parameters :
- Company :
@pipeline().parameters.PipeCompany - Year :
@pipeline().parameters.PipeYear - Month :
@pipeline().parameters.PipeMonth - Device ID :
@pipeline().parameters.PipeDeviceID - FileName :
@item().Name
- Company :
- Parameters :
- Schema mapped
- Source : FS_File
- Web Activity : Delete via Logic App
- URL :
@pipeline().parameters.LogicApp_FS_Delete - Method : POST
- Body :
@concat('{"filepath":"','myfolder/',pipeline().parameters.PipeCompany,'/',pipeline().parameters.PipeYear,'/',pipeline().parameters.PipeMonth,'/',pipeline().parameters.PipeDeviceID,'/',item().Name,'"}')
- URL :
- Copy Data : Actual Copy - Single File
- Items :
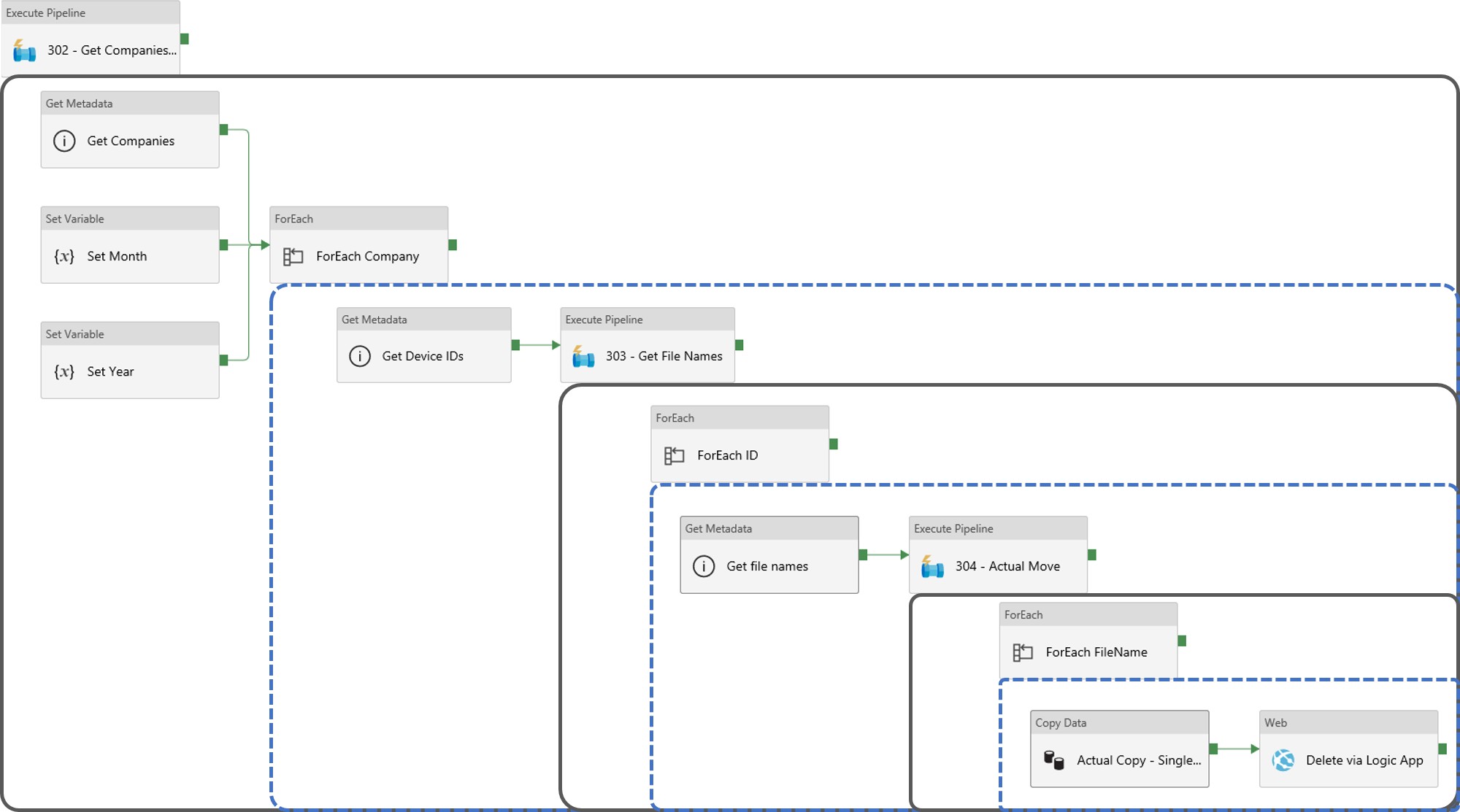
Actual pipeline Flow
Here is an illustration of the complete flow as implemented in ADFv2 across 4 pipelines:
Conclusion
The documentation of ADFv2 was a bit immature at the time of writing, so figuring some of the quirks of ADFv2 was a bit challenging. But if the solution we built is far from perfect, it is a good first iteration delivering on all the initial requirements.
