Architecture Decision Record for a hybrid batch data pipeline using Azure Data Factory v2 (ADF).
This is article is part of a series:
- Architecture discussion <- you are here
- ALM and Infrastructure
- Notable implementation details
Scenario
Scope
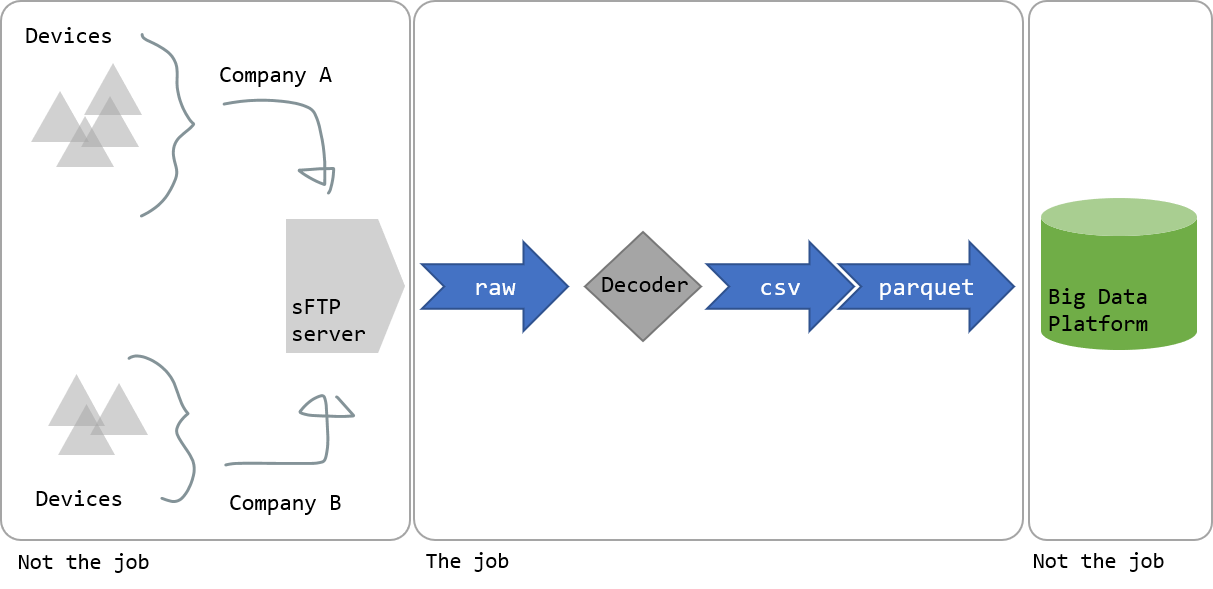
Big picture, we will design and build the central piece of an IoT ingestion pipeline using cloud based technologies.
In that scenario we are a service provider that aggregates, in a central big data platform, data generated on devices owned by multiple customers (Company A, Company B…).
This pipeline will take encoded files published hourly on a centralized sFTP server (one top folder per customer) decode them, convert them (csv to parquet) and move them to the ingestion folder of our big data platform.
Technical Requirements
- Encoded raw files are published every hour on a sFTP server in a Virtual Network
- They need to be decoded by a piece of software running on Windows: the decoder
- The resulting CSVs are to be converted into Parquet…
- …and moved to a big data environment for consumption
Additionally, the files need to be re-organized from a folder hierarchy (Company\Year\Month\Device ID\xyz.csv) to a flat structure(Staging\year_month_company_device_xyz.csv), for an easier ingestion in the big data platform.

General Approach
We will process the files in an hourly batch, as they are published every hour on the source server.
But by nature (IoT), these are events that should be streamed: the batch ingestion is just a current implementation detail. It is my conviction that the pipeline should be a streaming one.
That being said, a batch approach will be much easier to implement for the first iteration and will guarantee that we deliver on the required time-to-production.
We will need a cloud aware ETL to schedule and execute that job, some compute engines to move and process the files, and storage to host them.
Solution building blocks
We’ll start by picking an ETL as it’s the central component of the solution. It’ll dictate which compute engines we will be able to use, which in turns will put constraints on the storage we can access.
Cloud Aware ETL
Azure Data Factory v2 (ADFv2) will be used here. It will orchestrate the entire pipeline, and allow us to put multiple activities on a large selection of compute and storage services in a single control flow.
Additionally, it offers:
- a native sFTP connector
- a way to reach inside the VNet where the files are originally located and the decoding engine will be running (via a self-hosted integration runtime, see below)
- a native csv-to-parquet conversion engine via the Copy Activity
- NB: this is a temporary approach, data flows should be used for file processing but they are still in preview at the time of writing
We also wanted to test the product as it’s currently positioned as the default choice for batch integration in Azure.
Compute Engines
ADFv2 can call to multiple compute engines to execute activities:
- internal ones called Integration Runtimes (IR)
- external ones such as HDInsight, Databricks, Azure SQL via stored procedures…
All the native activities of ADFv2 require an IR. The good thing is that every factory comes with a default IR (autoResolve IR). The less good thing is that its networking configuration can’t be changed, and we will need to do that for the native sFTP activity to reach inside the VNet. To solve that issue we will provision a Windows VM in that VNet, install a self-hosted IR there, and register it with our Factory.
In the factory, when we’ll create the linked services for our different storage accounts (see Storage below), we will configure them to use the right IR (see connectVia property): either self-hosted (to reach in the VNet) or autoResolve (only one able to convert CSVs to Parquet).
At the time of writing there is no native activity to delete files in ADFv2 (Update 2019-03-01, now there is one, but officially it doesn’t support Azure File Storage). We will use a Logic App instead, following that strategy, but with a File Store connector. We tried a direct call to the File Store REST API delete endpoint from ADFv2 with a Web activity, but could not get the authentication to work (no MSI, contrary to blob). We also tried to call a Function, but the connectivity to a File Store from Functions is not straightforward (unsupported in the SDK at the time of writing, REST authentication is challenging).
Storage
The decoder runs on a Windows VM. It listens to a folder (A), grabs incoming files, processes them and outputs them in another folder (B).
Since the sFTP transfer is operated by ADFv2, the easiest setup will be for us to copy those files to an Azure File Store mounted as a drive (A) on the decoding VM. Another Azure File Store is mounted as the decoder output folder (B), and will be used as a source of the following copy activities.
The final staging folder will be an Azure Blob store, which is much easier to access from a Big Data platform.
Solution
Architecture
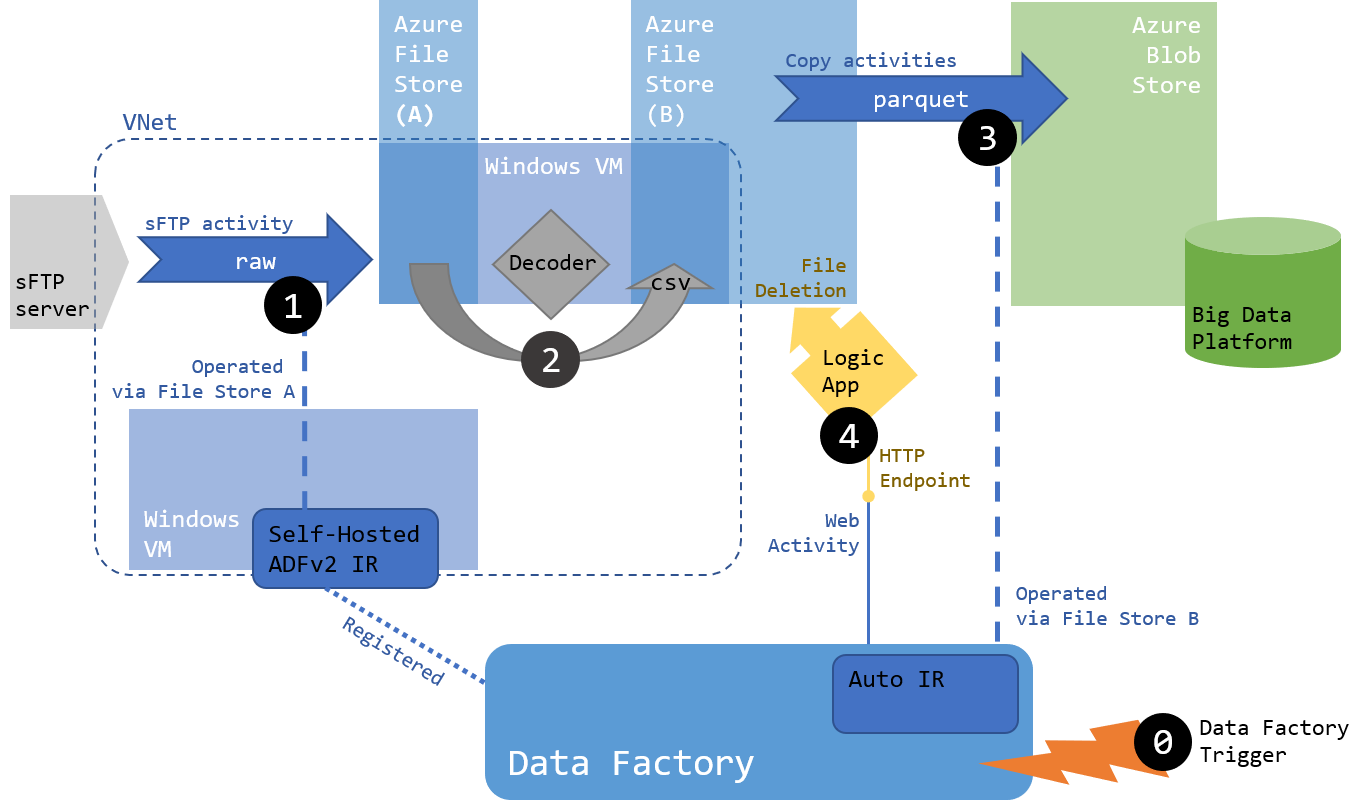
Regarding scheduling, here are some considerations on how each activity will be triggered:
- Step (1) can and should be called by an external trigger (0), scheduled to run hourly
- Step (2) is covered by the listener running process of the decoder, it doesn’t need to be triggered
- Which means that ideally step (3) and (4) should also be triggered by a listener. Sadly this feature is not easily supported on Azure File Store (either via ADFv2, Logic App or Function). This means we will need another trigger running on a schedule to export files. We decided to schedule that part to run every 15 minutes as a stopgap solution
Regarding storage:

Costs
Based of the expected volume of data, run frequency, and list of required services, we can use the Azure pricing calculator to get a fair estimate of the monthly costs (USD):
- Data Factory : 250$
- Logic Apps : 70$
- Storage : 140$
- VMs : 600$
- VNet : 2$
- Total : 1062$ (USD, monthly, running 24/7 every 15 minutes)
We won’t go into more details here, but this is a critical aspect of the solution that should be planned out, and tested. Some metrics used in the calculator are obscure, and only trying things out will give the comprehensive data required for long term budgeting.
Alternatives
There are tons of them, either going heavy-weight (cluster based via HDInsight, Databricks…) or light-weight (serverless via Function, Logic Apps…).
Up next
Architecture discussion- ALM and Infrastructure
- Notable implementation details
