Assembling a proactive notification system to monitor Azure Elastic Database Jobs and get alerted when one fails.
Azure Elastics Database Jobs provide the ability to run one or more T-SQL scripts in parallel, across a large number of databases, on a schedule or on-demand.
This product is a managed, trimmed-down version of SQL Server Agent. The SQL Agent itself being the scheduler of choice for maintenance operations, ETL processing, and other workloads on SQL Server.
Elastic jobs is in preview at the time of writing. A couple of features are still missing, alerting is one of them. Since one should always be proactively notified when one’s scheduled job fails, let’s see how to wire something up ourselves while we’re waiting for the product team to catch up.
Problem space
The features we need are:
- Getting an alert (email) when a job fails
- Only get notified once per failure, which means keeping a state of what’s been sent
- (Optional) Archiving run results, since the history is limited to 45 days in the service
Constraints
In terms of constraints, right now there are only 2 ways to get job execution results: via T-SQL or PowerShell.
Both are to be polled, meaning we will need to query those endpoints regularly and check for execution results ourselves. Push mode would be better, but since I really don’t want to create triggers on a managed table (if it’s even possible), there’s not really a choice.
The execution results are actually stored in the Job database, defined at the job creation time, in easily accessible tables.

figure 1 : Conceptual architecture of Azure Elastic Database Jobs
Components and solution
The algorithm we need is simple:
- On a time based trigger (every 5 minutes), do a check
- Poll the latest execution results from one of the endpoints
- For that, keep track of when the previous check was done, and filter out results before that timestamp
- (Optional) Archive those results in our own datastore
- Check for failures among those results, send an alert if there is any
- Poll the latest execution results from one of the endpoints
Which means we need a compute engine that has a time based trigger (or a hook to get called by one), a datastore and a notification system.
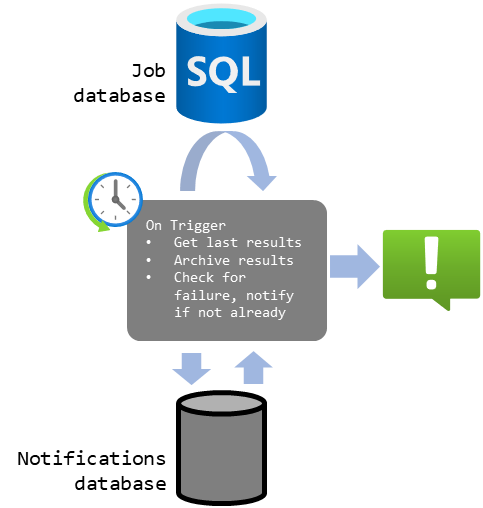
figure 2 : Components of the system
Here I decided on something simple:
- Using the Job database for storing the tables we need, side by side with the job history
- Instead of provisioning an additional DB as pictured above
- A PowerShell runbook running in Azure Automation as the compute
- But I decided on implementing the “business logic” in the database via a stored procedure rather than in the runbook
- I wanted all the logic to be sitting next to the data in the database, to be able to replace the runbook easily later. This is more about the ease of debugging, in 12 months, when I have forgotten everything about the project, than any other factor…
- Notify users via email (which requires a SendGrid account)
Some alternatives are Azure Functions (that I love but the feeling is not mutual) or Logic Apps (that was easy until I couldn’t figure out how to not send an email when no failures where found).
Areas of interest
Tables and stored procedures
In the Job database, I created the job_status table to keep track of the latest timestamp at which the check was performed. It’s a single row table that gets updated every time the notification job runs.
CREATE TABLE [dbo].[job_status](
[create_time] [datetime2](7) NOT NULL, -- Latest job execution time from job_executions
[update_time] [datetime2](7) NOT NULL -- When the check was performed
) ON [PRIMARY]
-- (re) Initializing job_status
TRUNCATE TABLE [dbo].[job_status]
INSERT INTO [dbo].[job_status]
([create_time]
,[update_time])
VALUES
('2020-09-11 22:02:26.4066667'
,GETDATE())
Then I created a stored procedure that would get the latest results from job_executions, filter it on job_status, and output the executions with status I don’t like.
CREATE PROCEDURE job_status_update
AS
BEGIN
-- Get the latest execution results in a temporary table
SELECT
j.job_name,
j.job_execution_id,
j.step_name,
j.lifecycle,
j.create_time
INTO #RecentExecutions
FROM jobs.job_executions j
-- MAX to protect against human error, it should be a single row table
LEFT JOIN (SELECT MAX(create_time) create_time FROM dbo.job_status) s
ON 1=1
WHERE j.create_time > COALESCE(s.create_time,j.create_time);
-- Update the tracking table
UPDATE dbo.job_status
SET
-- COALESCE to protect against no new executions in between checks
job_status.create_time = COALESCE((SELECT MAX(create_time) FROM #RecentExecutions),job_status.create_time),
job_status.update_time = GETDATE();
-- Return the results to the caller
SELECT * FROM #RecentExecutions WHERE lifecycle NOT IN ('Created','InProgress','Succeeded');
END
RETURN
GO
For testing purposes:
-- Reset job_status in the past
UPDATE dbo.job_status
SET
job_status.create_time = '2020-09-11 22:02:26.4066667',
job_status.update_time = GETDATE()
-- Check outputs
EXEC job_status_update;
PowerShell Runbook
Creating a runbook is easy, wiring up the whole thing could be easier.
Calling the database is straightforward, the easiest for me was to create a SQL login on the database and store the credentials in Key Vault.
Let’s not forget to assign a Key Vault access policy to the Automation Run As account service principal beforehand.
$adminLogin = "sqlPS"
$adminPassword = Get-AzKeyVaultSecret -VaultName "myKeyVaultName" -Name "kvTestSecret"
$serverInstance = 'myServer.database.windows.net'
$databaseName = 'myDatabase'
$sqlQuery = "EXEC job_status_update;"
$params = @{
'database' = $databaseName
'serverInstance' = $serverInstance
'username' = $adminLogin
'password' = $adminPassword
'query' = $sqlQuery
}
$results = Invoke-SqlCmd @params
if ($results){
# Send that email!
}
Sending the email is more complicated that it should, as it requires a SendGrid account.
Conclusion
Here we are, with a working alerting system for Azure Elastic Database Jobs.
Let’s not forget to create an Azure Monitor alert on the runbook itself, to get alerted when the alerting system itself fails.
It would be quite ironic otherwise.
